Spark runtime 단축TIP - Spark 이해하기
들어가며
OOO의 빅데이터 업무는 Apache Spark 에서 이루어집니다. 신입분들의 경우에는 처음 Spark를 접하신 분들이 많을텐데요. Spark는 분산 처리알아서 해줘서 빠름…과 같이 관념적으로만 이해하고 바쁜 업무에 치이다 보니 Spark환경에 대한 이해가 부족한 상태로 쿼리 작성하시는 분들이 대다수일 것으로 압니다. 저 또한 지난 1년간은 Spark 환경을 잘 모른체 냅다 쿼리만 작성 해왔습니다.
때문에 Spark에서 작업을 하며 불필요한 시간 소요, 시스템적 에러가 발생해도 영문을 모른체 기다리거나 Spark 시스템 담당자의 도움을 받아 해결 했습니다.
이번에 Spark 데이터 엔지니어 관련 수업을 들으면서 알게 된 적용하기 쉬우면서도 runtime 단축에 도움 될 만한 아래와 같은 TIP을 차차 공유하고자 합니다. 아래 방법에서 “쿼리 잘짜기”외 에는 감이 안오시는 분들은 이 글이 도움 되시리라 생각됩니다.
- 적절한 Spark Join 전략 최적화
- 적절한 Spark Partition 개수 및 크기 최적화
- 쿼리 잘짜기
- 등등..
이번 글에서는 위의 TIP을 이해하기 위해 알아야 할 Spark의 기본적인 개념을 다루겠습니다.
아래 목차대로 설명드리겠습니다.
- Spark 가 일하는 방식
- Spark의 Join 처리 방식
- 최적화를 수행하는 Catalyst optimizer
- 결론
1.Spark 가 일하는 방식
구성요소
Spark는 대표(Driver)가 여러 직원(Executor) 에게 업무(Task)를 분배하고 보고 받는 방식으로 일을 처리합니다.
이때 PM(클러스터 매니저)이 클라이언트의 업무를 받고 중간에서 업무에 필요한 수 만큼의 Executor를 dynamic하게 조절하며 리소스를 최적화합니다.
작업 방식
Spark의 작업 방식은 Shuffle을 하냐 안하냐 크게 두가지로 나뉩니다. 작업하는 데이터 크기나 연산 특성에 따라 데이터를 Executor간 복사하고 참고해서 작업 해야하는 경우가 있는데, 이를 Shuffle 이라 합니다.
Executor 간 작업이 필요하기 때문에, Shuffle이 필요한 작업은 대규모 네트워크 통신을 발생시켜 시간이 오래 걸립니다.
Spark 에서는 되도록이면 Shuffle이 일어나지 않는 방식으로 일을 최적화 합니다.
업무 단위
Executor는 부여 받은 업무(Job)를 Shuffle연산 여부에 따라 세부업무(Stage)의 세세부업무(Task) 단위로 쪼개 처리합니다. 이때 데이터가 큰 경우, 데이터를 Partition 단위로 쪼개서 업무를 합니다.
(자세한 내용은 이 1. 링크 2.링크 를 참고하세요)
- Spark의 작업방식은 Shuffle을 하냐 안하냐 크게 두가지로 나뉜다.
- Shuffle은 Executor간 네트워크 작업이 많은 고비용 연산이다.
- Spark 는 Shuffle을 안일으키는 방향으로 최적화 해서 일을 수행한다.

Spark의 Join 처리 방식
Spark의 작업 방식은 Shuffle을 하냐 안하냐로 나뉜다고 말씀드렸습니다.
마찬가지로 Spark가 Join 작업을 처리하는 방식도 Shuffle을 사용하는 Join이냐 아니냐로 나뉘는데요.
Spark가 Left join을 수행 할 때, Shuffle이 필요한 join이냐 아니냐에 따라 리소스 사용량과 runtime이 달라 질 수 있습니다.
일반적으로 데이터 사이즈에 따라서 Join 처리 방식이 정해지고, spark 환경을 추가 조작 하여 Shuffle 사용을 적절히 통제 할 수 있습니다.
(추가적인 처리 방식은 이 링크를 참조하세요.)
Spark에서 가장 많이 수행되는 Join 처리 방식 두가지만 살펴보겠습니다.
1) 셔플이 일어나는 Sort Merge Join
JOIN 하려는 두 데이터가 큰 경우, default로 수행되는 Shuffle 기반의 JOIN 기법입니다. Executor 간 데이터의 key값 복사가 일어나는 Shuffle 연산을 사용하므로 느립니다.
아래 그림에서 Dataset1,2에서 쪼개진 각각의 Partition A,B,C가 Executor1,2,3에 할당된다. Executor1을 보면, Dataset1의 PartitionB,C의 데이터를 참조하며 업무를 처리합니다. 즉 Shuffle이 발생하고 있습니다.

2) 셔플이 일어나지 않는 Broadcast Join
JOIN 하려는 데이터 중 한개가 작은 경우, default로 수행되는 메모리 기반의 JOIN 기법입니다.
작은 데이터를 Executor의 메모리에 직접 올려서 작업 되므로 추가적인 네트워크 통신이 발생하지 않아 빠릅니다.
아래 그림을 보면, thin table(초록)이 partition으로 쪼개지지 않고 Executor에 전체 복사되어 Executor간 서로의 데이터를 참조할 필요가 없게 됩니다. 즉 Shuffle이 일어나지 않아 매우 빠릅니다.

→ 적재적소에 Broadcast Join을 사용하면 runtime을 단축 시킬 수 있습니다!
2. 최적화를 수행하는 Catalyst Optimizer
Shuffle을 사용하지 않는 방식으로 최적화가 진행된다. Join이라는 작업을 할 때는 Shuffle이 일어나지 않는
Broadcast Join을 적절히 사용하면 좋다는 것을 알았습니다.
Spark는 똑똑하니까 알아서 적재적소에 Broadcast Join을 사용해줄까요? 바로 Catalyst Optimizer가 최적화를 어느정도는 진행 해줍니다. 어느정도라고 표현한 이유는 저희가 사용하는 Spark 2.x 에서는 특정 케이스에선 최적화가 되지 않습니다.
Spark 2.x 의 Catalyst Optimizer는 최종적인 쿼리 수행시간까지는 고려하지 않고, 쿼리 및 시스템(리소스)측면에서의 최적화는 진행 해주는데요. runtime까지 고려된 최적화는 Spark 3.x 부터 가능합니다.
Spark 1.x - rule based(쿼리적인 측면)
Spark 2.x - rule based + cost based(시스템적인 측면)
Spark 3.x - rule based + cost based + runtime based(수행시간 측면)
그러면 어떻게 최적화를 하는지에 대한 프로세스를 살펴봅시다.
아래 그림 처럼 쿼리를 입력(Query Plan) 받으면, Catalyst Optimzer가 쿼리를 최적화(Optimized Query Plan)를 해줍니다. 구체적으로는 4단계에 걸쳐 진행되는데요.
1. 쿼리의 vaild 여부를 확인하는 Logical Plan
2. fliter를 순서를 바꾸는 등의 쿼리 차제의 최적화가 일어나는 Optimized Logical Plan
3. 시스템적으로 어떻게 적용 시킬지 여러개의 적략(Join 전략 등..)을 만들고, Cost를 비교하는 Physical Plan
4. Cost model에서 1등한 Selected Physical Plan 이 최종적으로 수행됩니다.
(자세한 내용은 링크를 참조하세요.)

Catalyst Optimizer 최적화 모습 직접 확인해보기
우리가 모르는 사이에 Catalyst Optimizer가 열심히 최적화를 진행해주고 있었습니다.
이번에는 실제로 Catalyst가 최적화를 진행하는지 직접 살펴봅시다.
- Optimized Logical Plan에서 실제로 쿼리의 순서가 바뀌는 최적화가 일어나는지
- Physical Plan에서 JOIN 전략을 잘 설정 하는지
같은 결과를 출력하고 쿼리의 순서만 바꾼 두 코드를 비교해보겠습니다.
코드는 다음과 같습니다.
// 코드1 : 필터링 나중 실행
small_sample1
.join(small_sample2, small_sample1("key") === small_sample2("key"))
.filter("age > 11") //--조인 후 필터링 실행....
.show()
//코드2 : 필터링 먼저 실행
small_sample1
.filter("age > 11") //--조인 전 필터링 실행....
.join(small_sample2, small_sample1("key") === small_sample2("key"))
.show()SQL 버젼 코드는 다음과 같습니다.
%sql
-- 코드1
SELECT *
FROM SMALL_SAMPLE1 A
LEFT JOIN SMALL_SAMPLE2 B ON A.KEY = B.KEY
WHERE A.AGE > 11
-- 코드2
SELECT *
FROM (SELECT * FROM SMALL_SAMPLE1 WHERE AGE > 11) A
LEFT JOIN SMALL_SAMPLE2 B ON A.KEY = B.KEY
두 개의 Small 테이블을 JOIN 할 때, 필터링의 순서만 바꿔서 실행시킨 코드 입니다.
결과는 당연히 동일할테고, JOIN 작업 리소스가 덜 드는 코드2가 더 좋은 코드입니다.
- 코드1 - JOIN 하고 나서 필터링 실행
- 코드2 - JOIN 하기 전 필터링 실행 (Good Code)
explain 를 통해 logical,physical plan을 확인해보겠습니다.
위 scala 코드에서 show() 대신 explain(true)로 바꾸면 catalyst의 수행 계획을 확인 할 수 있습니다.
// 수행 계획 확인
// 코드1 : 필터링 나중 실행
small_sample1
.join(small_sample2, small_sample1("key") === small_sample2("key"))
.filter("age > 11") //--조인 후 필터링 실행....
.explain(true)
//코드2 : 필터링 먼저 실행
small_sample1
.filter("age > 11") //--조인 전 필터링 실행....
.join(small_sample2, small_sample1("key") === small_sample2("key"))
.explain(true)결과는 아래와 같습니다.


애초에 잘 짠 코드2의 수행계획은analyzed ,Optimized Logical Plan 에서 동일하게 Filter 후 Join 을 수행합니다.
이미 잘 짰으므로 쿼리 수정이 일어나지 않았습니다.
코드 1의 수행계획을 보겠습니다.
analyzed logical plan에서는 처음 짠 코드 순서대로 Join 후 Filter 순으로 계획되어있지만, Optimized Logical Plan에서 쿼리가 최적화 되어 Filter 후 Join을 하도록 수행계획이 변경 되었습니다.
그리고 small data니까 코드1,2에서 모두 JOIN 전략도 알아서 Broadcast Join으로 설정된 것을 볼 수 있습니다.
마지막으로, Spark web ui을 통해서 실제로 best Physical plan을 수행했는지 확인해 보겠습니다.(경우에 따라 Physical plan 이 바뀌는 경우가 있습니다. 다음 글을 확인해주세요.)
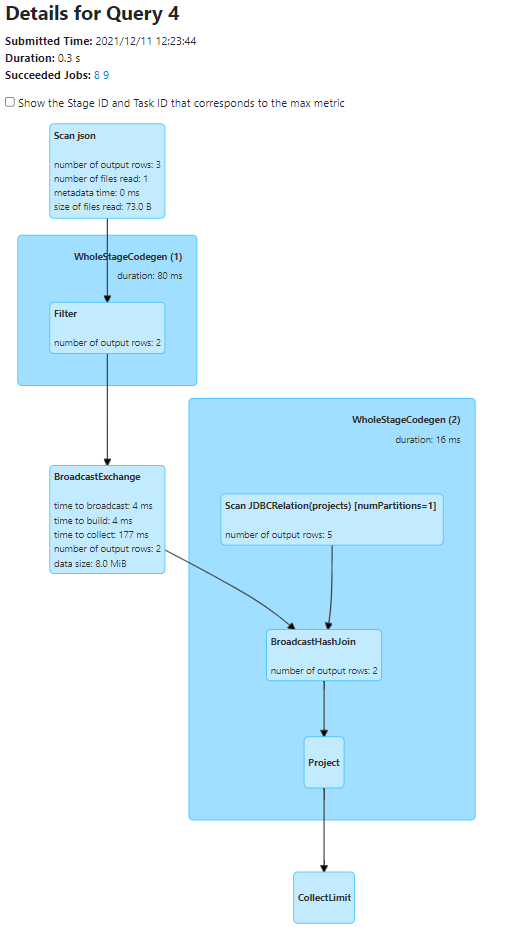

Spark web ui 에서도 실제로, 두 코드 모두 동일하게 필터링 후 Broadcast Join 이 수행 되었습니다.
마치며
지금까지 Spark 의 업무 처리 방식부터 Catalyst Optimizer 가 최적화 하는 모습을 직접 살펴보았습니다.
하지만 앞서 말했듯이 OOO가 사용하고 있는 Spark 2.x 에선 모든 경우에 대해서 Join 전략 최적화가 잘 일어나는것은 아닙니다. 특정 케이스에서는 불필요한 Join 시간이 발생하는경우도 있습니다.
다음 글에서는 data size 별 테스트를 해보며 runtime을 줄일 수 있는 방법을 설명하겠습니다.
결론
- Catalyst Optimizer 쿼리 순서를 바꾸는..등 어느정도는 최적화해준다.
- 특히, Small data를 Join 할 때는 Broadcast Join이 자동으로 수행되어 최적화 된다.
- 특정 경우에 최적화가 안되는 경우도 있다. 어떻게 해결하면 되는지는 JOIN 방식을 강제로 지정하는 방법 ..등 이 있다.
(기회가 된다면, 다루도록 하겠다)